
⚠️ 공부한 내용을 정리하는 공간입니다. 설명이 부족하거나 옳바르지 못한 부분이 있을 수 있습니다. 옳바르지 못한 내용을 발견하셨다면 댓글로 알려주시길 부탁드립니다. 수정하도록 하겠습니다.
오늘의 사족
12월은 묘하게 들뜨는 달입니다. 어둡고 무섭게만 느껴지는 겨울의 밤을 유독 환하게 밝혀주기 때문일까요?
그리고 길거리에 울려퍼지는 캐롤이 마음을 따뜻하게 녹여주는 느낌이 듭니다.
그래서 저는 언제나 저의 플레이리스트에 캐롤을 저장합니다. 12월의 추억을 캐롤이 저 대신 간직해주는 느낌이라서 마음이 지치고 힘들 때 캐롤을 틀곤 합니다. 그런다고 나아지는 건 아니지만 캐롤을 듣는 순간만큼은 들뜬 행복감이 듭니다. 그게 어딥니까
어찌됐든 얼마 안 남은 2023년 열심히 달려 봅시다!
< 목차 >
1. Instruction Architecture
1-1. opcode와 operand
1-2. opcode의 유형
1-3. Addressing Mode(주소지정방식)
1. Instruction Architecture
CPU가 어떻게 명령어를 수행하는지 그 과정을 설명하는 글을 보면 CPU가 메모리에서 읽어오는 명령어의 구조가 opcode와 operand로 이루어져 있는 걸 확인할 수 있다.

컴퓨터는 명령을 수행할 때 명령에 필요한 데이터(operand)와 데이터를 어떻게 처리할 것인지에 대한 뜻을 담은 데이터(opcode)를 읽어오고 해석해서 명령을 수행한다.
컴퓨터가 명령을 읽어오고 해석하고 수행하는 과정은 인간이 명령을 수행하는 과정과 같다.
예를 들어 누군가 필자에게 "집에서 가장 가까운 편의점에 가서 콜라를 사와라"는 명령을 했다고 가정해보자!

이때 '집에서 가장 가까운 편의점'과 '콜라', '집'은 명령을 수행하는 데 필요한 데이터이다. 그리고 '가서'와 '사고', '돌아간다'는 나의 행동을 제어하는 명령이다. 필자는 위 명령을 수행하는 데 있어서 먼저 1단계 명령인 집에서 가장 가까운 편의점에 가는 행동부터 수행할 것이다. 그런 다음 콜라를 사는 행동을 수행한 뒤 집에 돌아가면 필자는 위 명령을 수행한 것이다.
컴퓨터도 인간처럼 명령을 수행하는데 필요한 데이터(operand)와 연산(opcode)을 구분하여 명령을 수행한다.
1-1. opcode와 operand
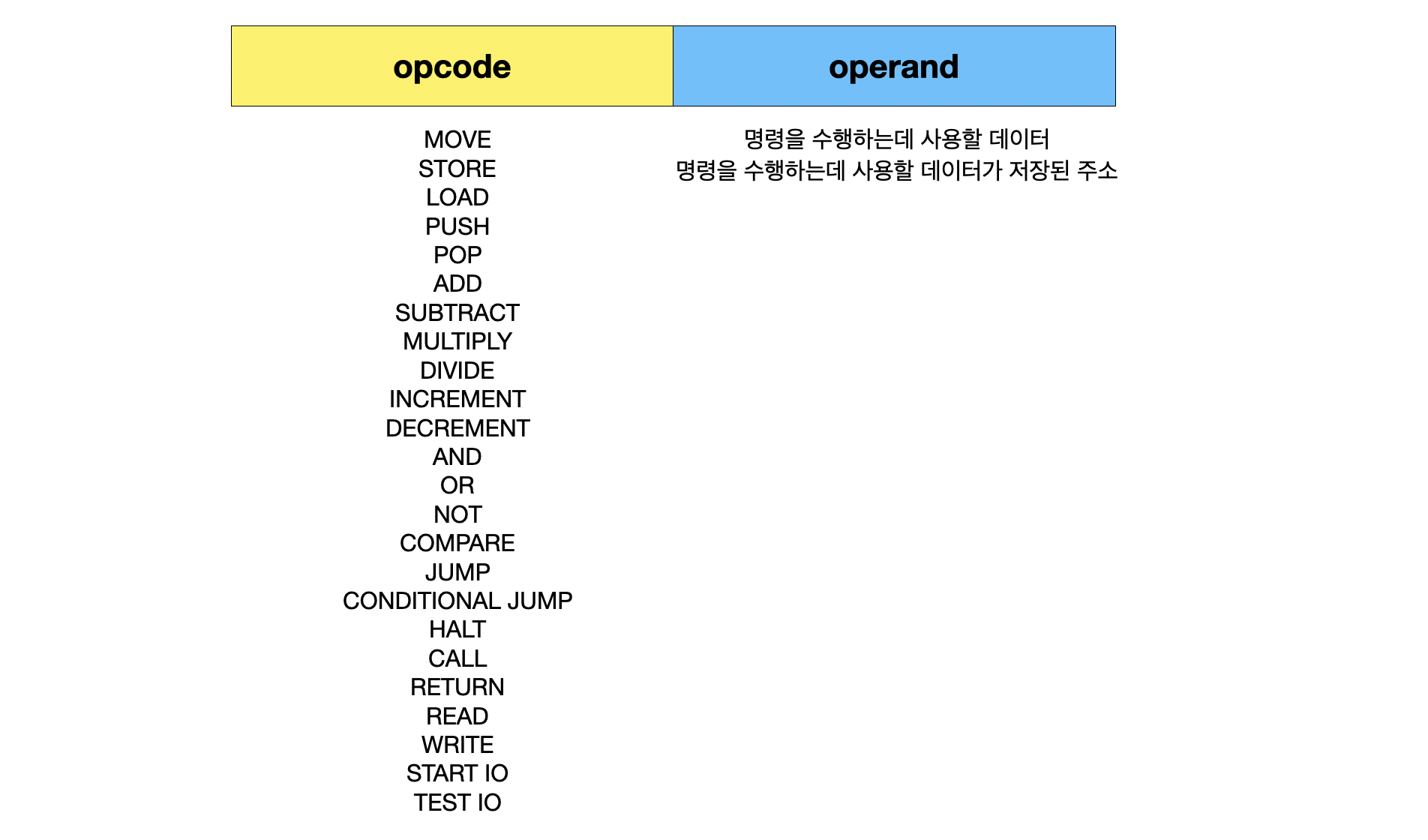
opcode는 CPU가 데이터를 어떻게 처리할 것인지에 대한 명령을 담은 데이터를 의미한다.
operand는 CPU가 명령을 수행하는 데 있어서 필요한 데이터를 의미한다. 데이터 그 자체일수도 데이터가 담긴 주소일수도 있다.
연산을 수행하는 데 있어서 데이터가 필요하지 않는 경우도 있다. 반대로 데이터가 여러 개 필요한 경우도 있을 것이다.
그래서 operand에 해당하는 필드가 아예 없을 수도 여러 개일수도 있다.
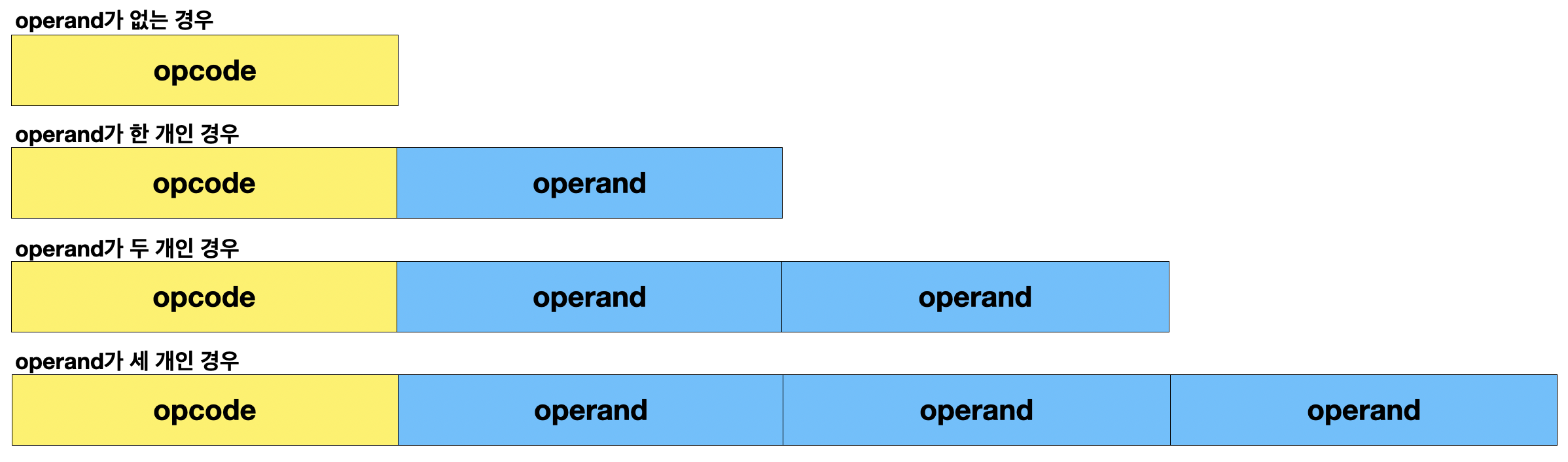
1-2. opcode의 유형
opcode는 데이터를 어떻게 처리할 것인지에 대한 연산을 담은 데이터이다.
여기서 연산은 단순히 더하고 빼는 것 외에도 많은 연산이 존재한다. opcode가 수행하는 연산으로 어떤 유형이 있는지 알아보자!
① 데이터 전송
- MOVE: 데이터를 옮겨라
- STORE: 데이터를 저장하라
- LOAD(FETCH): 메모리에 있는 데이터를 CPU로 가져와라
- PUSH: 스택에 데이터를 저장하라
- POP: 스택에서 데이터를 꺼내와라
② 산술/논리 연산
- ADD / SUBTRACT / MULTIPLY / DIVIDE : 덧셈, 뺄셈, 곱셈, 나눗셈을 하라
- INCREMENT / DECREMENT: operand에 1을 더하라/ operand에 1을 빼라
- AND / OR / NOT : 논리 연산을 수행하라
- COMPARE: 두 데이터를 비교하라 (숫자 or 참과 거짓)
③ 제어흐름(control flow) 변경
- JUMP: 특정 주소로 PC를 옮겨라
- CONDITIONAL JUMP: 조건에 부합하면 특정 주소로 PC를 옮겨라
- HALT: 프로그램 종료해라
- CALL: 돌아올 주소를 저장한 다음 특정 주소로 PC를 옮겨라
- RETURN: CALL을 호출할 때 저장했던 주소로 PC를 되돌려라
④ 입출력 제어
- READ(INPUT): 특정 입출력 장치로부터 데이터를 읽어라
- WRITE(OUTPUT): 특정 입출력 장치로 데이터를 써라
- START IO: 입출력 장치를 시작하라
- TEST IO: 입출력 장치를 테스트해라
1-3. Addressing Mode(주소지정방식)
위에서 명령어의 구조가 어떻게 이루어져 있는지 설명할 때 operand는 연산에 필요한 데이터 그 자체일수도 데이터가 담긴 주소일수도 있다고 했다.
굳이 왜 데이터가 담긴 주소값을 저장하는지 의문이 생긴다. 그냥 연산에 필요한 데이터 그 자체만 저장해서 명령을 수행하는 게 더 빠르지 않나? 왜 데이터가 담긴 주소를 또 저장해서 CPU가 메모리에서 데이터 값을 찾는 번거로운 일을 해야 하나
흠...
만약 누군가가 다음과 같이 명령을 하면 어떻게 수행할 것인가?

너무 많은 정보를 암기로 기억하는 것은 한계가 있을 것이다. 필자의 경우 위와 같은 명령을 받는다면 얼마 안 가 까먹어버리고 말 것이다.
그런 경우를 대비하여 필자는 무엇을 사야하는지 그 데이터를 따로 메모지에 적어둘 것이다. 그런 다음 메모지를 주머니에 넣고 편의점에 도착하면 주머니에서 메모지를 꺼내 무엇을 사야 하는지 확인할 것이다.
컴퓨터도 같다. 컴퓨터도 operand에 데이터를 저장하기 위한 용량이 제한되어있다. 그래서 operand에 데이터가 담긴 주소를 저장하는 것이다.
이제 그러면 operand에 데이터가 담긴 주소를 어떤 방식으로 지정하는지에 대해서 알아보자!
즉시 주소 지정 방식 (immediate addressing mode)

연산에 사용할 데이터를 operand에 직접 지정하는 방식이다. 연산에 사용할 데이터를 직접 operand 필드에 명식했기 때문에 명령을 수행하는 속도가 빠르다. 다만 표현할 수 있는 데이터의 크기가 작아진다는 단점이 있다.
직접 주소 지정 방식 (direct addressing mode)

operand 필드에 데이터가 저장된 주소를 직접 지정하는 방식이다.
표현할 수 있는 데이터의 크기가 커졌다. 다만 이제는 표현할 수 있는 *유효 주소에 제한이 생긴다.
유효 주소(effective address)란 연산에 필요한 데이터가 저장된 주소를 말한다.
간접 주소 지정 방식 (indirect addressing mode)
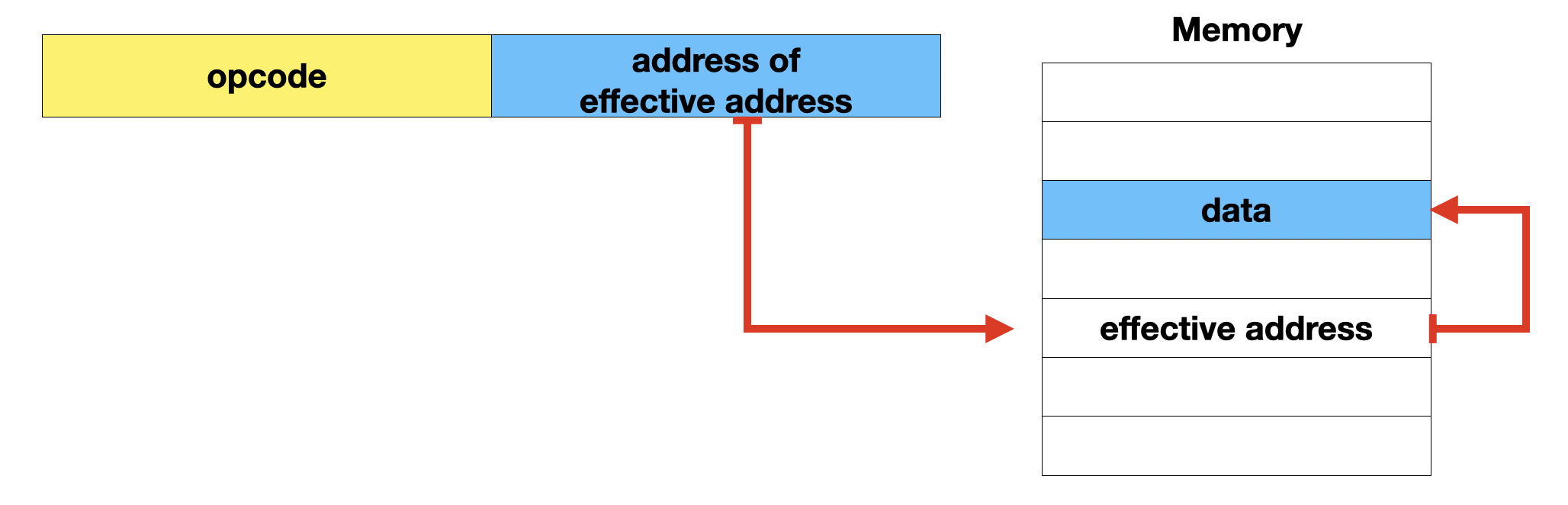
유효 주소의 주소를 operand 필드에 지정하는 방식이다.
표현할 수 있는 유효 주소 범위가 넓어졌다. 다만 메모리에 접근하는 빈도가 늘어 느려진다.
레지스터 주소 지정 방식 (register addressing mode)

연산에 필요한 데이터를 저장한 레지스터를 operand 필드에 지정하는 방식이다.
레지스터 간접 주소 지정 방식 (register indirect addressing mode)
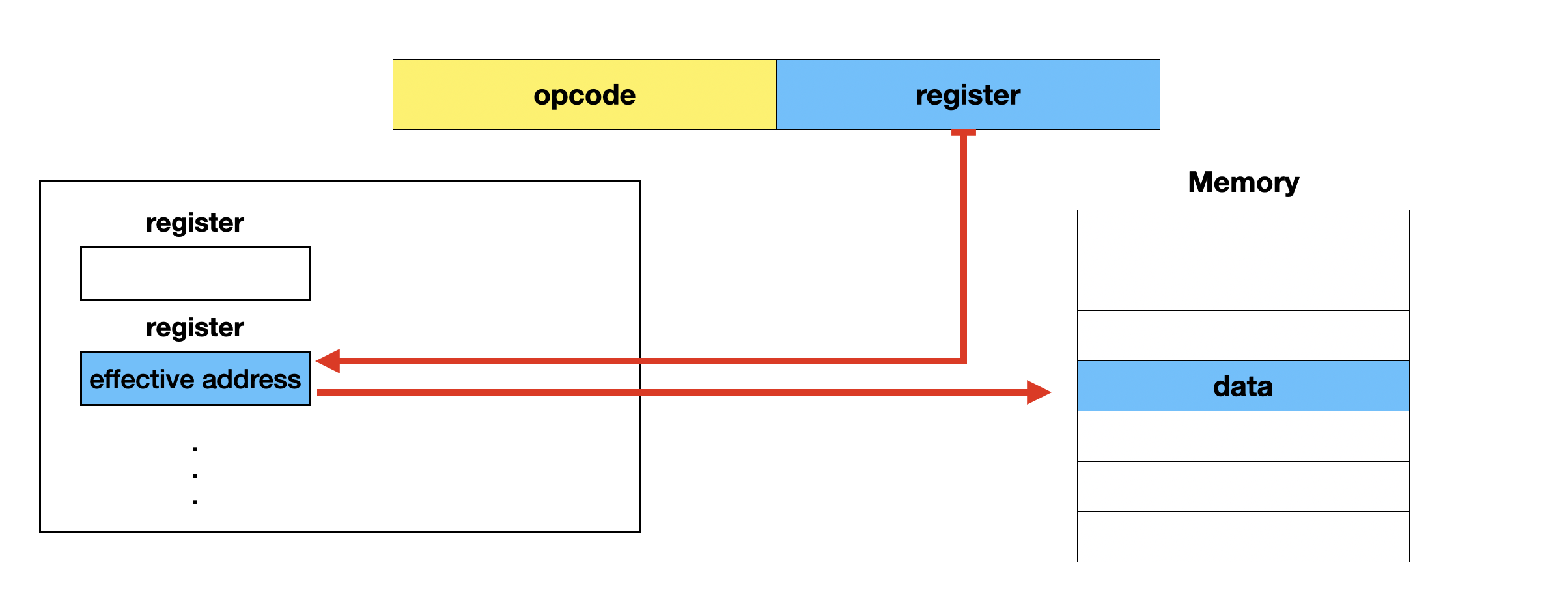
유효주소를 저장한 레지스터를 operand 필드에 지정하는 방식이다.
메모리에 두 번 접근하는 간접 주소 지정 방식과 달리 레지스터 간접 주소 지정 방식은 레지스터를 거쳐서 메모리에 한 번만 접근하기 때문에 간접 주소 지정 방식보다 명령 수행 속도가 빠르다.
스택 주소 지정 방식 (stack addressing mode)
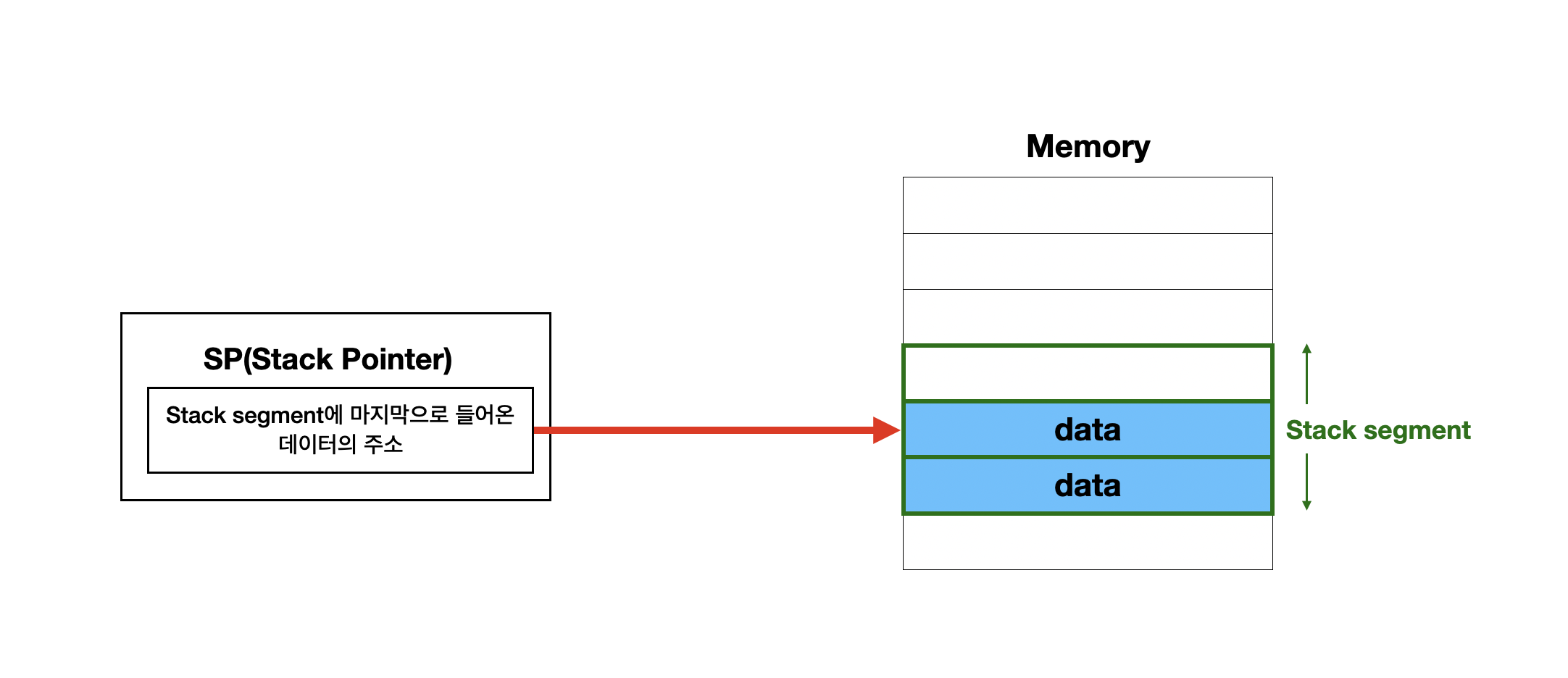
stack과 stack pointer(SP)를 이용한 주소 지정 방식
변위 주소 지정 방식 (displacement addressing mode)
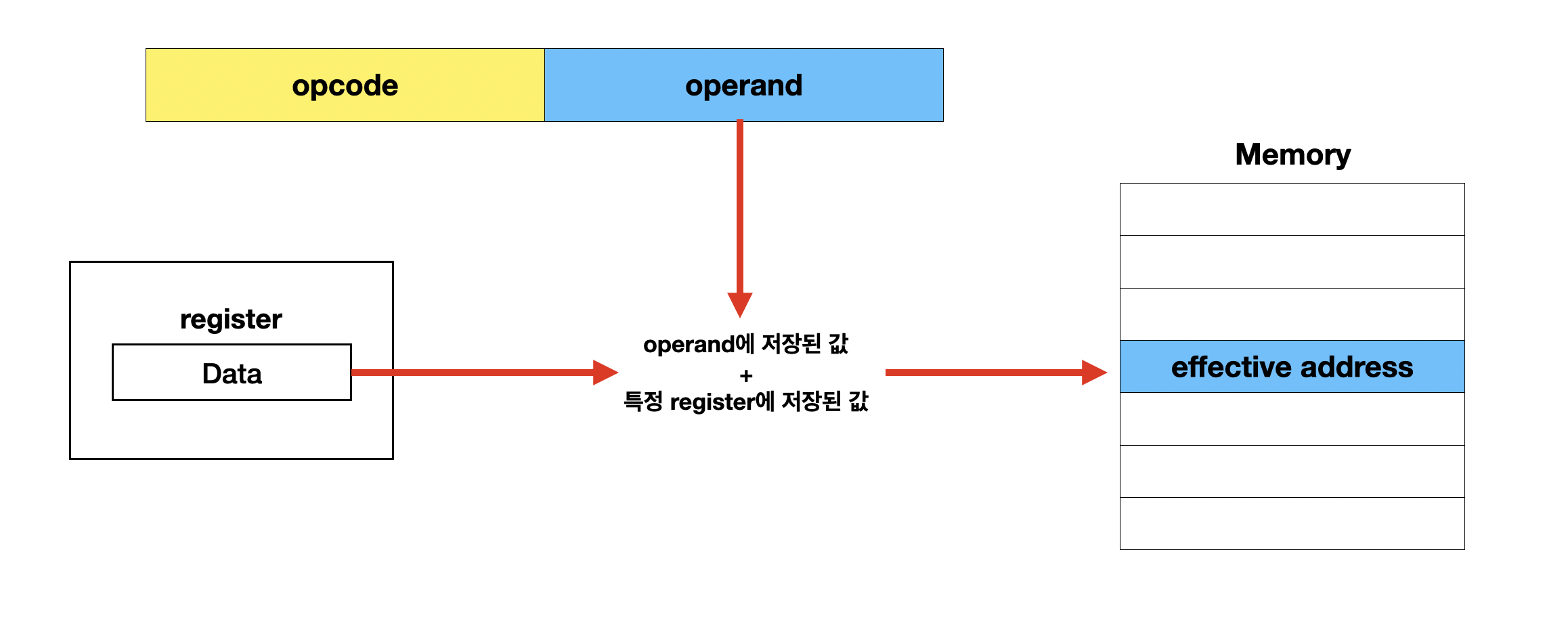
변위 주소 지정 방식은 operand 필드의 주소와 특정 register 값을 더해서 유효 주소 구하는 방식이었다.
이때 어떤 register의 값을 더하냐에 따라 상대 주소 지정 방식과 베이스 레지스터 지정 방식으로 구분된다.
상대 주소 지정 방식 (relative addressing mode)

상대 주소 지정 방식은 operand와 PC(Program Counter) 값을 더하여 유효 주소를 구하는 방식이다.PC의 값은 명령어를 수행하고 마칠 때 1씩 증가하기 때문에 유효 주소가 저장된 주소는 상대적이다.
베이스 레지스터 지정 방식 (base-register addressing mode)

베이스 레지스터 지정 방식은 operand와 Base-Register 값을 더하여 유효 주소를 구하는 방식이다.