
⚠️ 공부한 내용을 정리하는 공간입니다. 설명이 부족하거나 옳바르지 못한 부분이 있을 수 있습니다. 옳바르지 못한 내용을 발견하셨다면 댓글로 알려주시길 부탁드립니다. 수정하도록 하겠습니다.
오늘의 사족
Happy New Year~! 2024년 새해를 맞았습니다! TMI이지만 저는 사실 별 감흥이 없습니다. 크리스마스라 해서 들뜨고 새해라 해서 새롭게 리프레시하는 감정을 잘 느끼지 못합니다. 그냥 평소와 같습니다. 제가 생각하기에 순간의 행복은 순간입니다. 행복이라는 감정이 저에게 있어서 오래 머물러주지 않습니다. 그나마 성취감은 제가 목적을 이루기 위해 노력한 과정이 있기에 오래 머물러주는 것 같습니다. 그러니 제가 이렇게 되도록이면 글을 매일 올리는 것이랄까요? 어찌 됐든 새해를 맞이한 건 사실이니 모두 복 많으십쇼~!
1. RAID란?
IT산업이 발전함에 따라 기업이 저장해야 하는 정보의 양이 많아지고 또한 저장하는 정보 중에는 개인 정보, 결제 정보와 같은 민감한 정보도 포함되어 있다. 그렇기 때문에 기업이 단순히 정보를 하드디스크에 저장하는 건 너무 무모한 행위일 것이다. 이럴 때 사용하는 기술 중 하나가 RAID이다. RAID는 HDD와 SSD를 사용하는 기술로 데이터의 안전성, 성능향상을 위해 여러 개의 물리적 보조기억장치를 하나의 논리적 보조기억장치처럼 사용하는 기술이다.
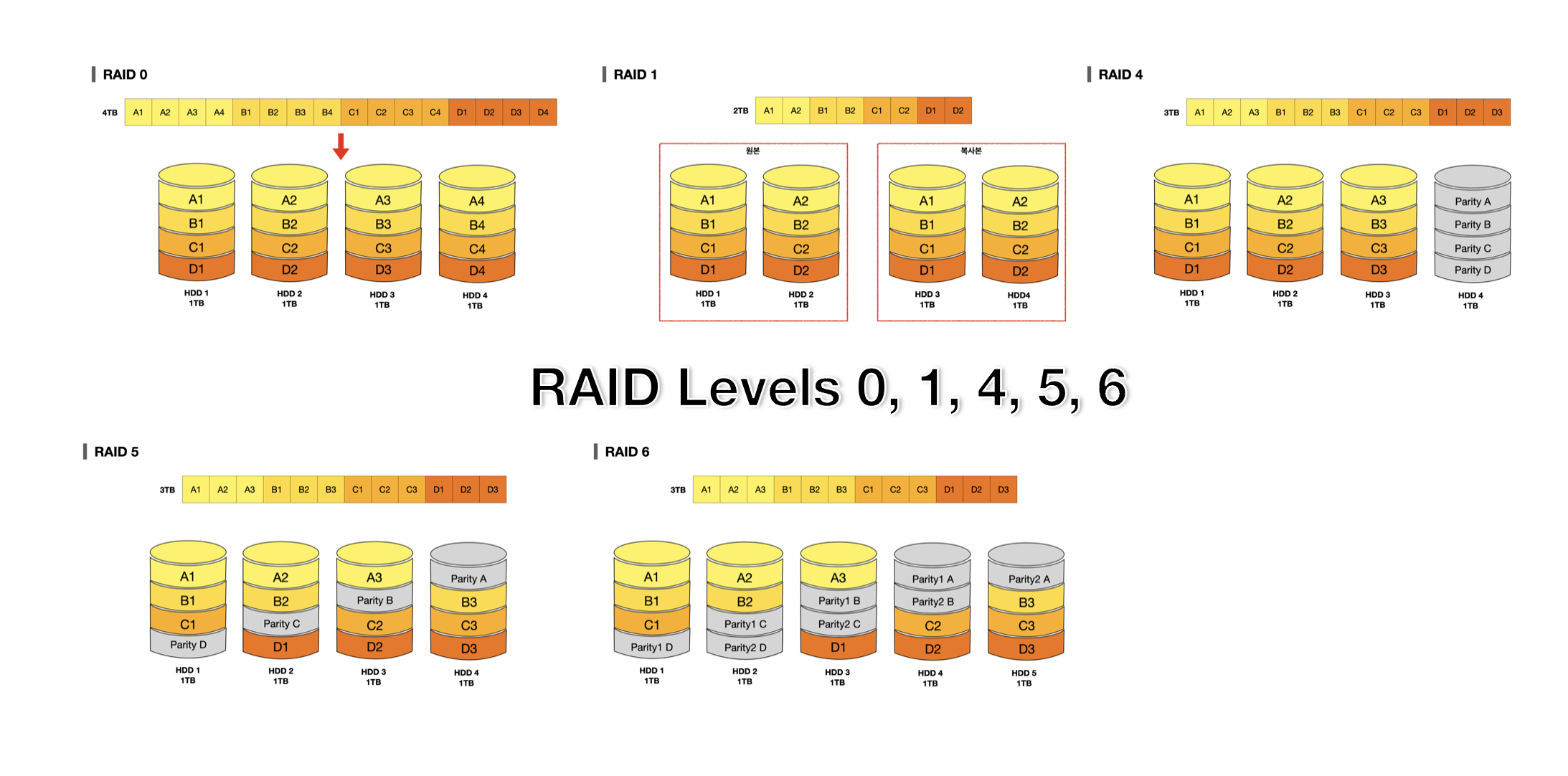
여러 개의 HDD나 SSD를 마치 하나의 장치처럼 사용하는 RAID를 구성하는 방법은 다양하다. RAID의 구성 방법을 RAID 레벨이라 표현하는데 대표적으로 RAID 0, RAID 1, RAID 2, RAID 3, RAID 4, RAID 5, RAID 6, RAID 10, RAID 50 등이 있다. 이 중에서 가장 대중적인 RAID Levels 0, 1, 4, 5, 6에 대해 알아보겠다.
1-1. RAID의 종류
종류를 알아보기 전에 RAID에서 사용되는 용어를 이해할 필요가 있다.
Striping: 줄무늬처럼 분산하여 데이터를 저장하는 것
Mirroring: 거울처럼 완전한 복사본을 만드는 것
Parity(= Checksum): 오류를 검출하고 복구하기 위한 정보
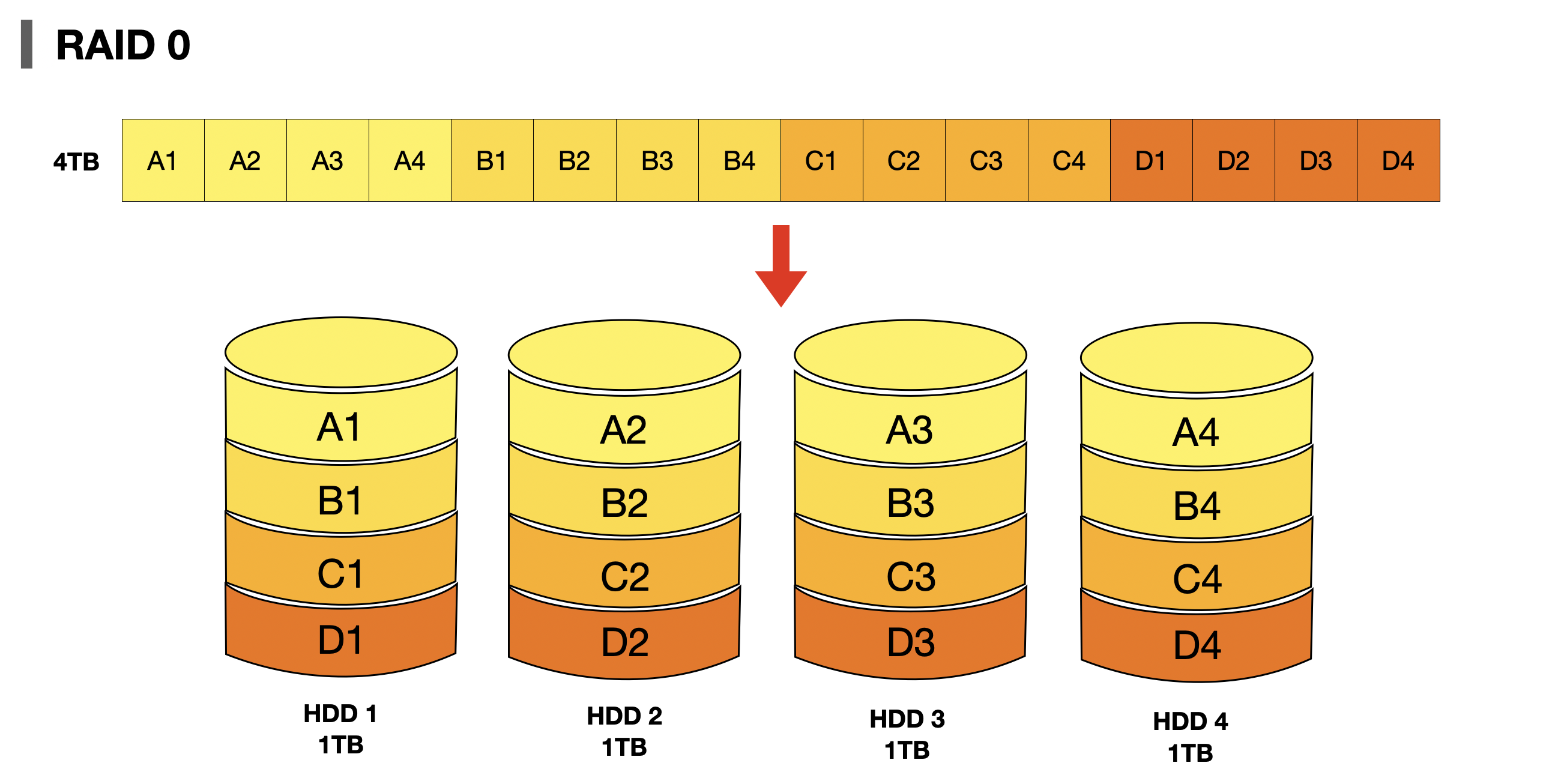
RAID 0은 여러 개의 보조기억장치에 데이터를 단순히 나누어 저장하는 구성방식이다. 위의 경우 데이터를 분산하여 저장하는 스트라이핑(Striping)을 하였다. 이렇게 분산되어 저장된 데이터를 스트라입(Stripe)이라 한다.
👍🏻 Advantages
- 저장된 데이터를 읽고 쓰는 속도가 빨라진다 "[1] Performance boost for read and write operations"
- 저장 공간 낭비가 없다. "[1] Space is not wasted as the entire volume of the individual disks are used up to store unique data"
👎🏻 Disadvantages
- 저장된 정보가 안전하지 않기 때문에 RAID 0으로 구성된 HDD 중 하나라도 문제가 생기면 다른 모든 HDD의 정보를 읽는데 문제가 생긴다. "[1] There is no redundancy/duplication of data. If one of the disks fails, the entire data is lost."
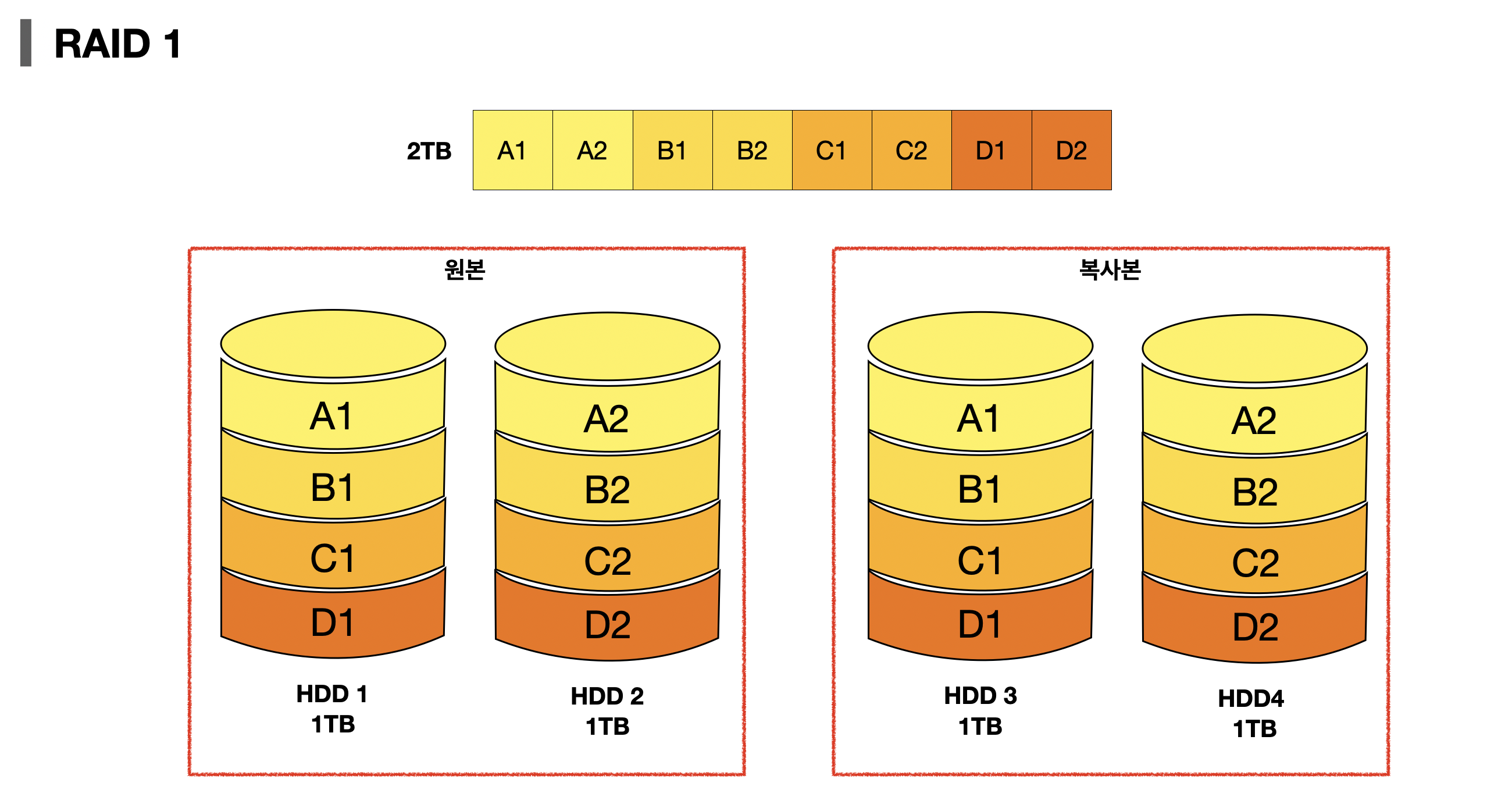
RAID 1은 복사본을 만드는 구성방식이다. 거울같이 동일한 복사본을 만드는 RAID 1은 Mirroring(미러링)이라고 불리기도 한다.
👍🏻 Advantages
- "[1] Data can be recovered in case of disk failure"
- "[1] Increased performance for read operation"
👎🏻 Disadvantages
- 데이터를 두 번 써야하기 때문에 쓰기 속도는 RAID 0보다 느리다. "[1] Slow write performance"
- 똑같은 데이터를 두 번에 걸쳐 쓰기 때문에 HDD 개수가 한정된 경우 사용 가능한 용량이 적어진다. 즉, 공간 낭비가 심하다. "[1] Space is wasted by duplicating data which increases the cost per unit memory"
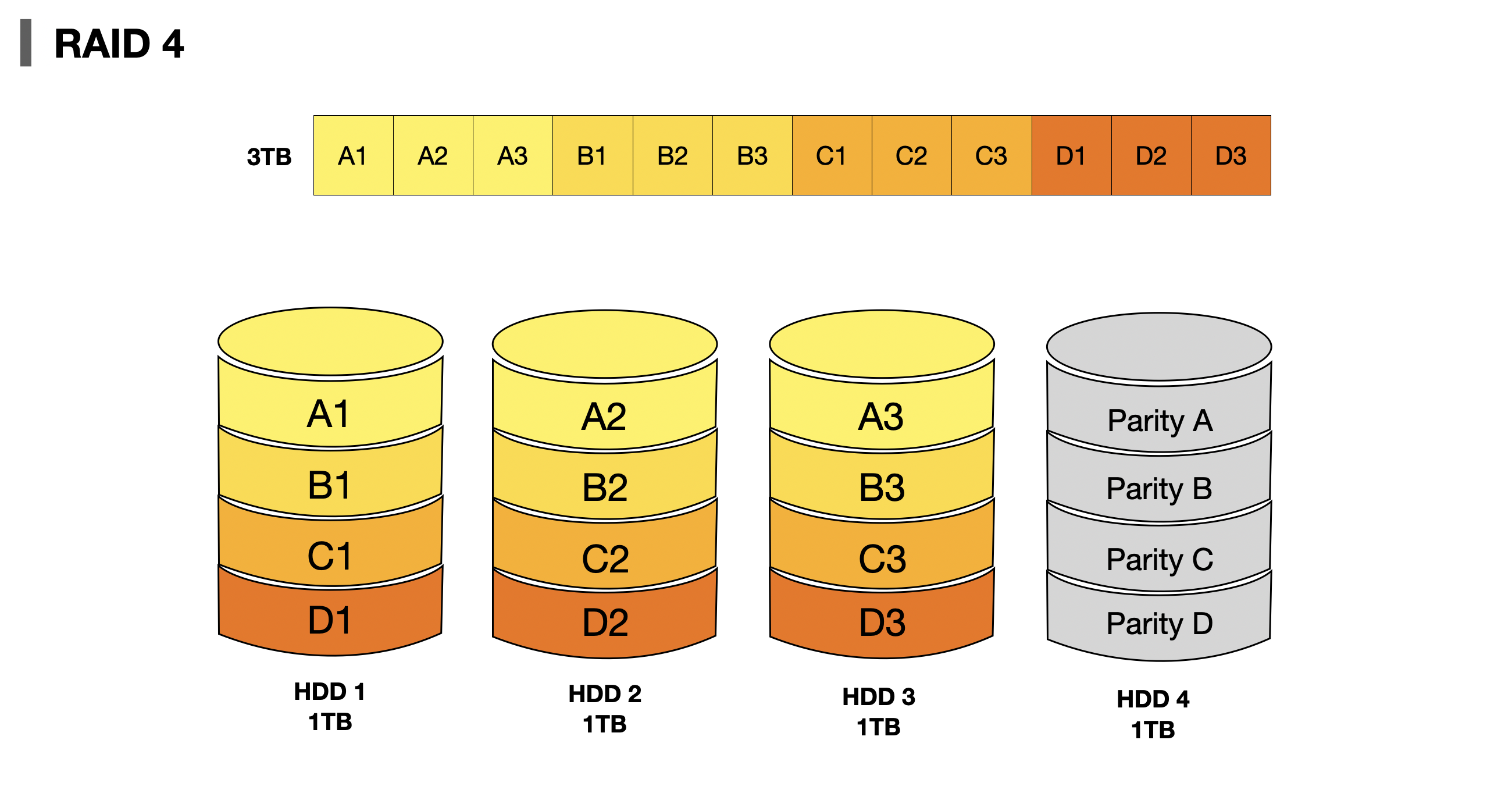
RAID 4는 오류검출과 복구를 위한 정보(Parity)를 저장한 장치를 두는 구성방식이다. 위 그림에서 패리티를 저장한 장치 HDD4를 이용하여 다른 장치들(HDD 1~3)의 오류를 검출하고 오류가 있다면 복구한다. 패리티를 저장한 장치를 따로 둠으로써 RAID 1보다 적은 하드디스크로 더 많은 데이터를 안전하게 보관할 수 있다.
👍🏻 Advantages
- "[1] Efficient data redundancy in terms of cost per unit memory"
- "[1] Performance boost for read operations due to data stripping"
👎🏻 Disadvantages
- 새로운 데이터가 저장될 때마다 패리티를 저장하는 디스트에도 데이터를 쓰기 때문에 패리티 저장장치에 병목 현상이 발생하여 쓰는 연산이 늘리다. "[1] Write operation is slow"
- "[1] If the dedicated parity disk fails, data redundancy is lost"
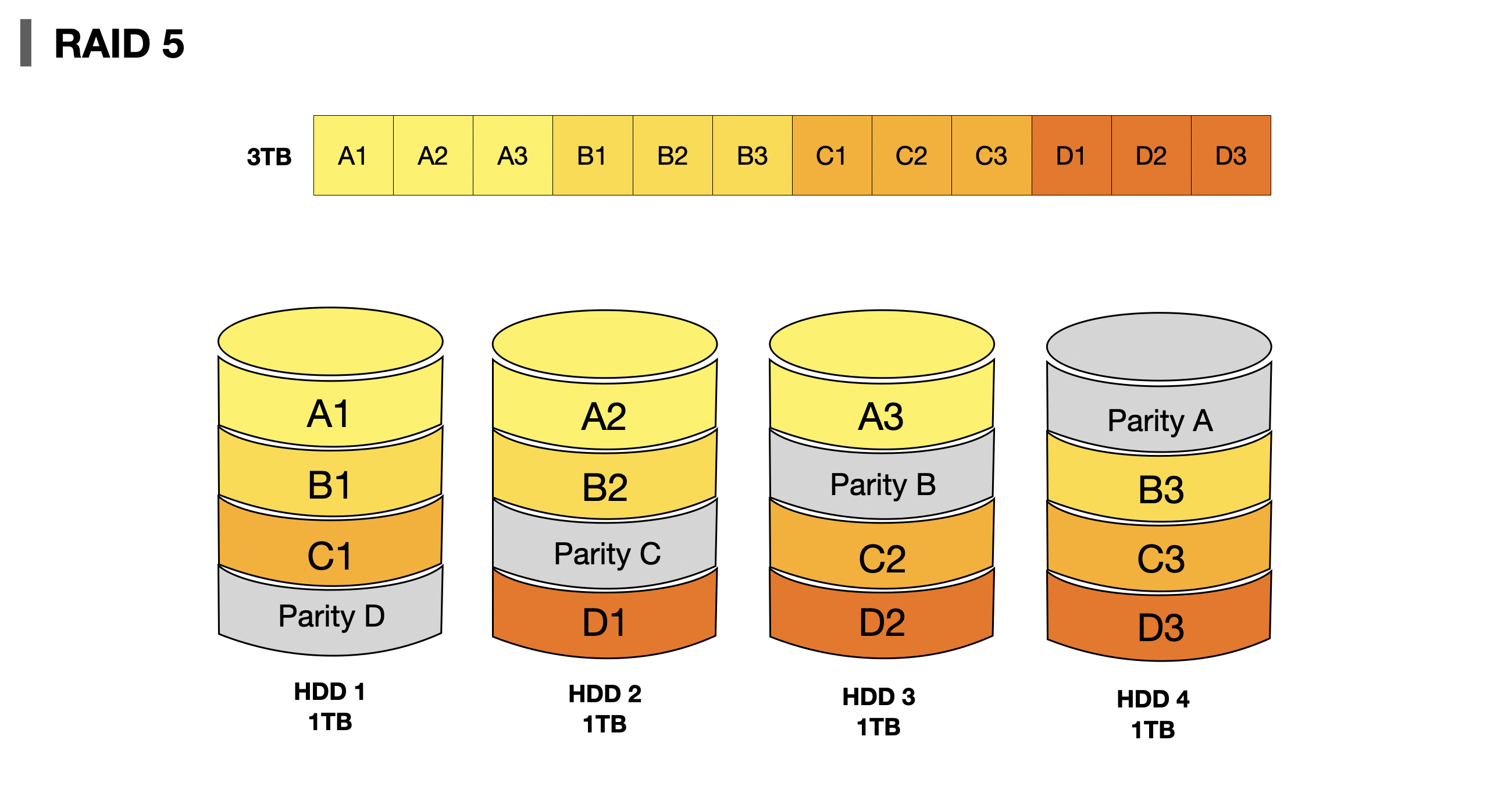
RAID 5는 패리티 정보를 분산하여 저장하여 RAID 4의 문제인 병목현상을 해소하는 구성방식이다.
👍🏻 Advantages
- "[1] All the advantages of RAID 4 plus increased write speed and better data redundancy"
👎🏻 Disadvantages
- "[1] Can only handle up to a single disk failure"
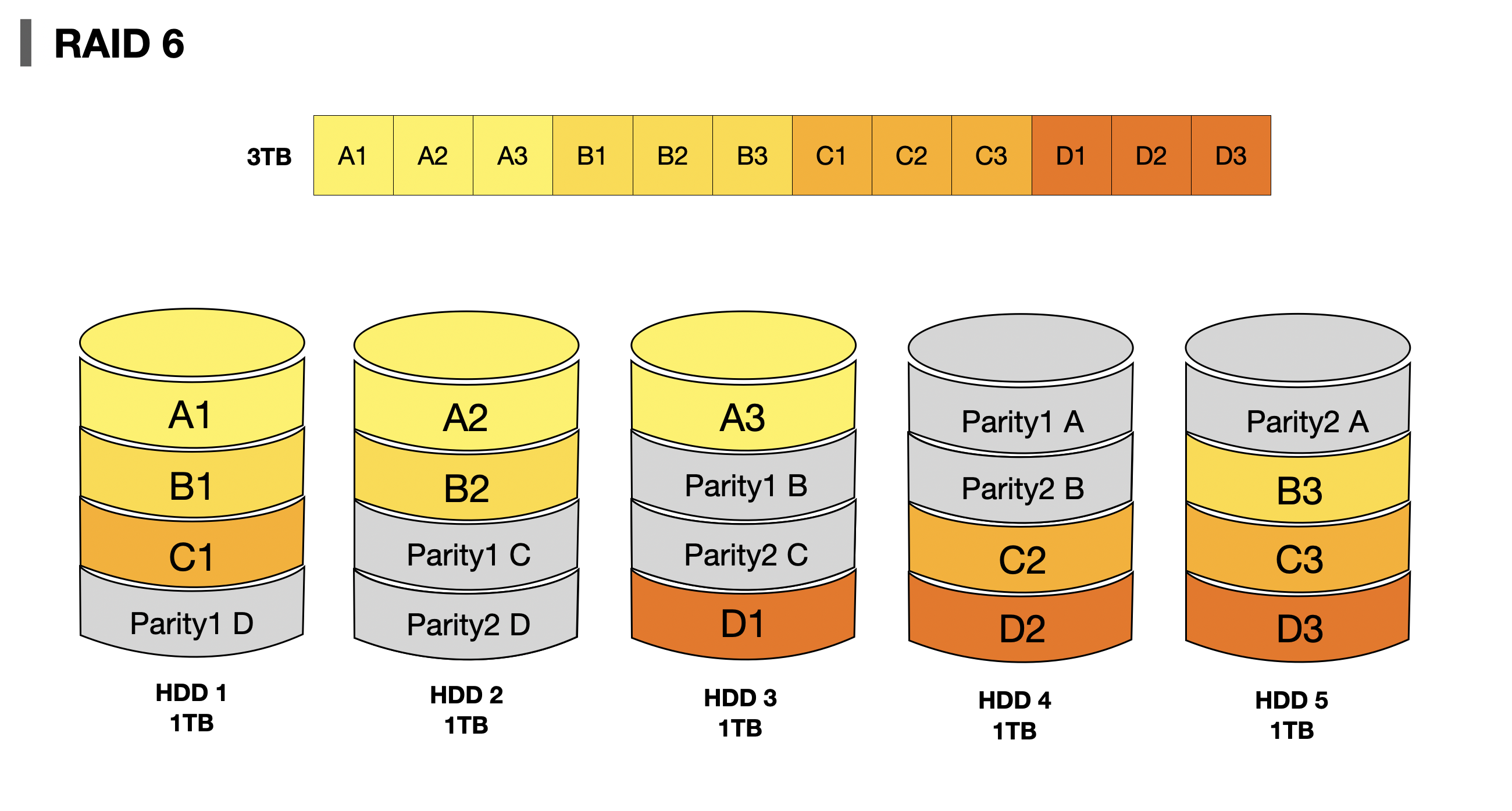
RAID 6은 RAID 5와 기본적인 구성은 같으나 서로 다른 두 개의 패러티를 두는 구성방식이다. 오류 검출 및 복구를 할 수 있는 수단이 늘어났으므로 RAID 5보다 안전한 구성방식이다. RAID 6는 데이터 저장 속도는 좀 늦더라도 데이터를 더 안전하게 보관하고 싶을 때 사용하는 방식이다.
👍🏻 Advantages
- "[1] Better data redundancy. Can handle up to 2 failed drives"
👎🏻 Disadvantages
- "[1] Large parity overhead"
<참조>
- VCCLHosting Challenge the limits (2021.09.18) Know the different levels/modes of RAID (0,1,2,3,4,5,6) [Website]
- golinuxhub (2014.04.09) RAID levels 0, 1, 2, 3, 4, 5, 6, 0+1, 1+0 features explained in detail [Website]
<출처>
[1] Ashik Bin Kader Nirjhar (2020.12.30) RAID levels 0, 1, 4, 5, 6, 10 explained [Website]
'🖥️ Computer Science > Computer Architecture' 카테고리의 다른 글
| [Computer Architecture] 목차(Index) (0) | 2024.01.03 |
|---|---|
| [Computer Architecture] I/O Device(입출력장치)에 대하여 (0) | 2024.01.02 |
| [Computer Architecture] 보조기억장치에 대하여_ HDD, Flash Memory (0) | 2023.12.31 |
| [Computer Architecture] Cache Memory(캐시 메모리)에 대하여 (0) | 2023.12.22 |
| [Computer Architecture] RAM에 대하여_DRAM, SRAM, SDRAM, DDR SDRAM (0) | 2023.12.21 |